近段时间来,AI 对话助手在语言任务上取得了不小的进展。这种显著的进步不只是基于 LLM 强大的泛化能力,还应该归功于指令调优。这涉及到在一系列通过多样化和高质量指令的任务上对 LLM 进行微调。
借助指令调优获得零样本性能的一个潜在原因是,它内化了上下文。这很重要,特别是当用户输入跳过常识性的上下文时。通过纳入指令调优,LLM 获得了对用户意图的高度理解,即使在以前未见过的任务中也能表现出更好的零样本能力。
然而,一个理想的 AI 对话助手应该能够解决涉及多种模态的任务。这需要获得一个多样化和高质量的多模式指令跟随数据集。比如,LLaVAInstruct-150K 数据集(也被称为 LLaVA)就是一个常用的视觉 - 语言指令跟随数据集,它是使用 COCO 图像、指令和从 GPT-4 中获得的基于图像说明和目标边界框的响应构建的。但 LLaVA-Instruct-150K 具有三个局限性:有限的视觉多样性;使用图片作为单一视觉数据;上下文信息仅包含语言形态。
为了推动 AI 对话助手突破这些限制,来自新加坡南洋理工大学、微软雷蒙德研究院的学者们提出了多模态上下文指令调优数据集 MIMIC-IT,这是一个包含 280 万条多模态上下文指令 - 相应对的数据集,涵盖各种现实生活场景。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文地址:https://arxiv.org/pdf/2306.05425.pdf
此外,为了高效地生成指令 - 响应对,研究者还介绍了「Sythus」,这是一个受 self-instruct 方法启发的指令 - 响应注释的自动化 pipeline。Sythus 采用系统信息、视觉注释和上下文中的例子来指导语言模型(GPT-4 或 ChatGPT)根据视觉语境生成指令 - 响应对,针对视觉语言模型的三个基本能力:感知、推理和规划。此外,英文的指令和响应被译成七种语言,以支持多种语言的使用。
特别值得注意的是,研究者在 MIMIC-IT 上训练了基于 OpenFlamingo 的多模态模型「Otter」。通过 ChatGPT、人类两个方面的评估,Otter 的多模态能力超越了近期的其他视觉 - 语言模型。
在一系列 Demo 中,研究者展示了 Otter 的多模态问答能力:
Q:接下来出哪张牌?
A:八筒。这样你就能留着四条和五条,等着凑成顺子。

Q:我想着陆了,怎么操作?
A:按一次左下按钮,左转,要着陆时拉右边的手刹。

Q:接下来怎么办?
A:把球传到中路,跑到球门,寻找进球机会。

接下来,让我们看看研究细节。
MIMIC-IT 数据集包括 280 万个多模态指令 - 响应对,涵盖了基本能力:感知、推理和计划。每个指令都伴随着多模态的对 话背景,使在 MIMIC-IT 上训练的 VLM 能够在交互式指令中表现出很好的熟练度,并能进行零样本的概括。
话背景,使在 MIMIC-IT 上训练的 VLM 能够在交互式指令中表现出很好的熟练度,并能进行零样本的概括。
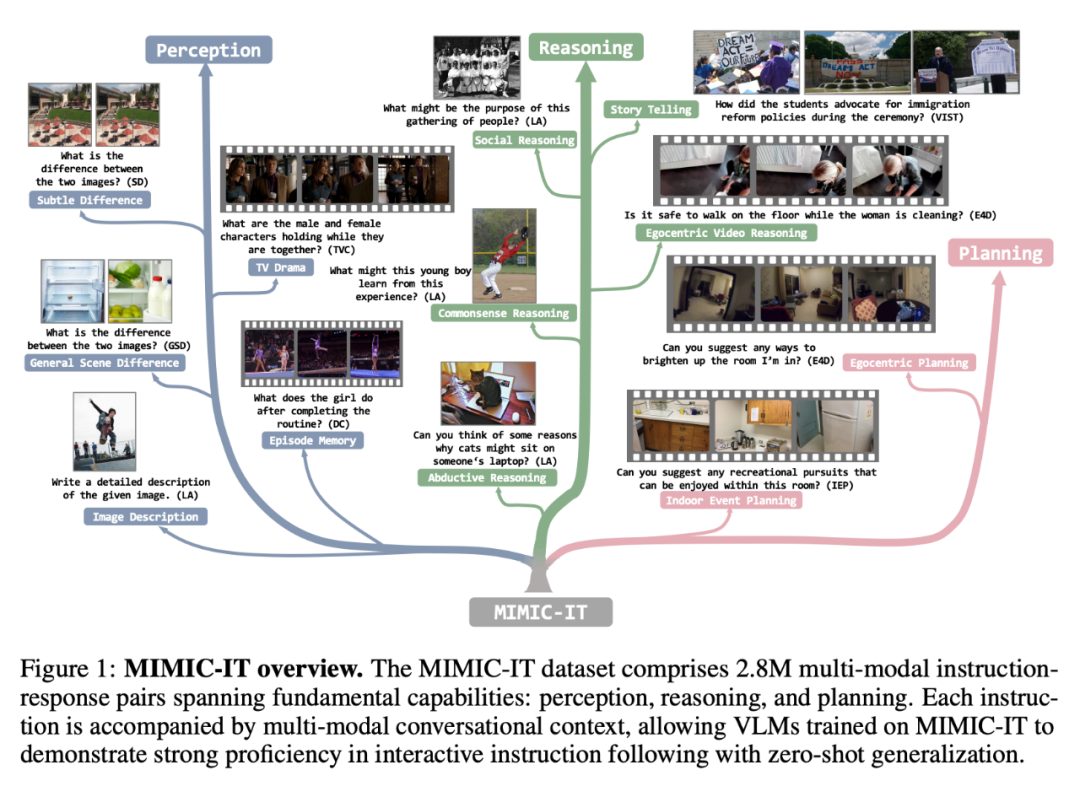
相比于 LLaVA,MIMIC-IT 的特点包括:
(1) 多样化的视觉场景,包含了一般场景、自我中心视角场景和室内 RGB-D 图像等不同数据集的图像和视频;
(2) 多个图像(或一个视频)作为视觉数据;
(3) 多模态的上下文信息,包括多个指令 - 响应对和多个图像或视频;
(4) 支持八种语言,包括英文、中文、西班牙文、日语、法语、德语、韩语和阿拉伯语。
下图进一步展示了二者的指令 - 响应对对比(黄色方框为 LLaVA):

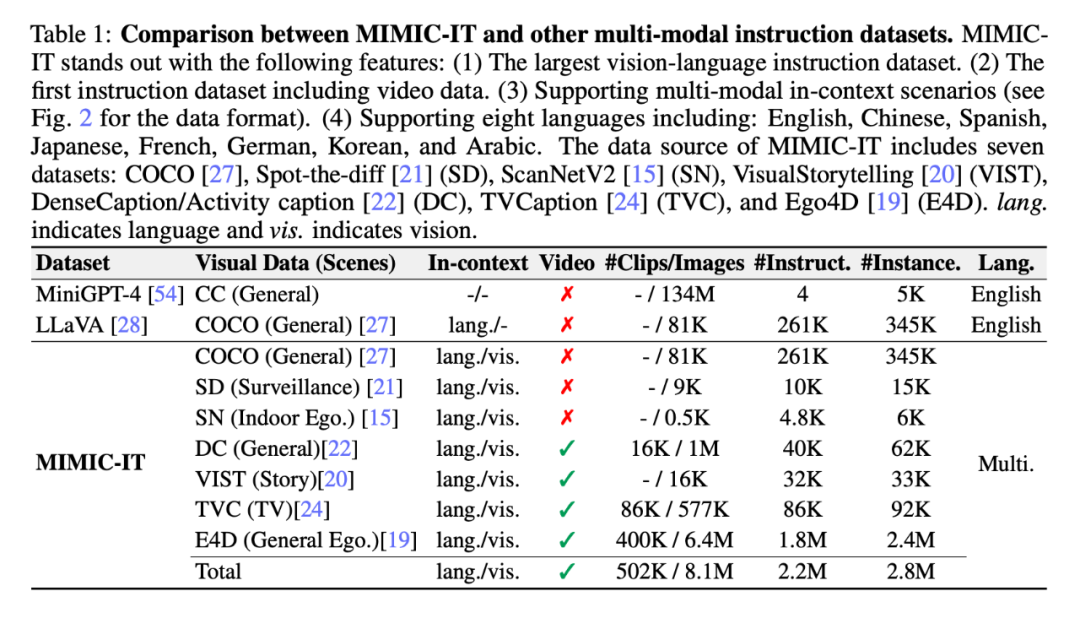
如表 1 所示,MIMIC-IT 的数据源来自七个数据集:COCO、Spot-the-diff (SD)、ScanNetV2 (SN)、VisualStorytelling (VIST) 、DenseCaption/Activity caption(DC)、TVCaption(TVC)和 Ego4D(E4D)。「上下文」这一列的「lang.」表示语言,「vis.」表示视觉。
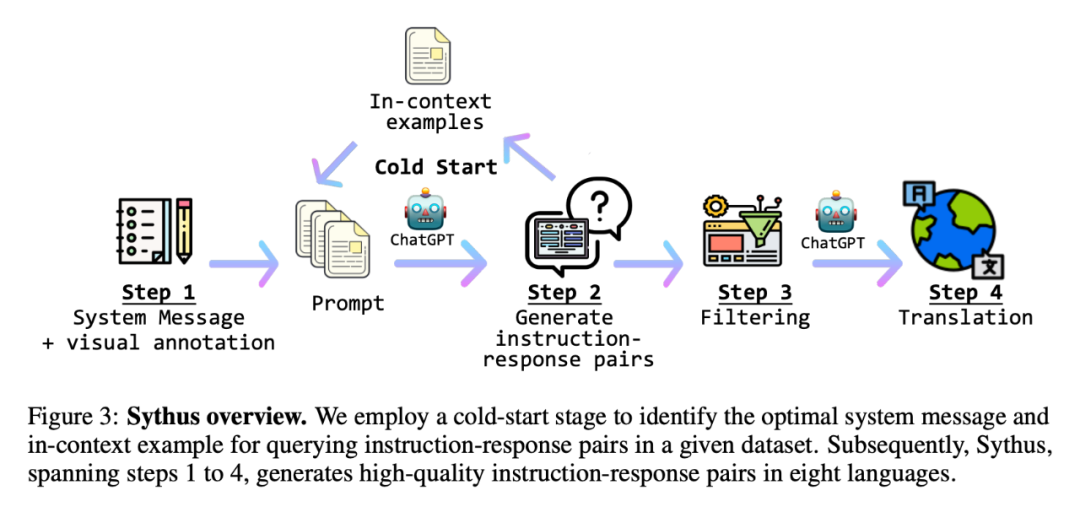
同时,研究者提出了 Sythus(图 3),这是一个自动化 pipeline,用于生成多种语言的高质量指令 - 响应对。在 LLaVA 提出的框架基础上,研究者利用 ChatGPT 来生成基于视觉内容的指令 - 响应对。为了确保生成的指令 - 响应对的质量,该 pipeline 将系统信息、视觉注释和上下文中的样本作为 ChatGPT 的 prompt。系统信息定义了所生成的指令 - 响应对的预期语气和风格,而视觉注释则提供了基本的图像信息,如边界框和图像描述。上下文中的样本帮助 ChatGPT 在语境中学习。
由于核心集的质量会影响后续的数据收集过程,研究者采用了一个冷启动策略,在大规模查询之前加强上下文中的样本。在冷启动阶段,采用启发式方法,仅通过系统信息和视觉注释来 prompt ChatGPT 收集上下文中的样本。这个阶段只有在确定了令人满意的上下文中的样本后才结束。在第四步,一旦获得指令 - 响应对,pipeline 会将它们扩展为中文(zh)、日文(ja)、西班牙文(es)、德文(de)、法文(fr)、韩文(ko)和阿拉伯语(ar)。进一步的细节,可参考附录 C,具体的任务 prompt 可以在附录 D 中找到。
随后,研究者展示了 MIMIC-IT 数据集的各种应用以及在其上训练的视觉语言模型 (VLM) 的潜在能力。首先,研究者介绍了使用 MIMIC-IT 数据集开发的上下文指令调优模型 Otter。而后,研究者探索了在 MIMIC-IT 数据集上训练 Otter 的各种方法,并讨论了可以有效使用 Otter 的众多场景。
图 5 是 Otter 在不同场景下的响应实例。由于在 MIMIC-IT 数据集上进行了训练,Otter 能够为情境理解和推理、上下文样本学习、自我中心的视觉助手服务。

最后,研究者在一系列基准测试中对 Otter 与其他 VLM 的性能进行了比较分析。
ChatGPT 评估
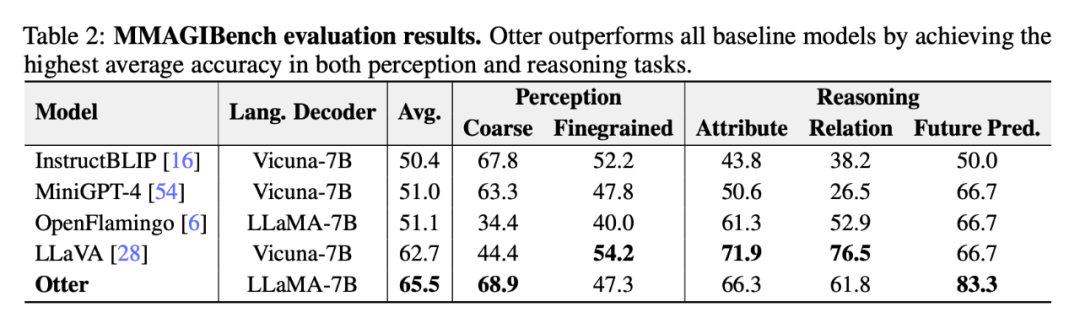
下表 2 展示了研究者利用 MMAGIBench 框架 [43] 对视觉语言模型的感知和推理能力进行广泛的评估。
人类评估
Multi-Modality Arena [32] 使用 Elo 评级系统来评估 VLM 响应的有用性和一致性。图 6 (b) 显示 Otter 展示了卓越的实用性和一致性,在最近的 VLM 中获得了最高的 Elo 评级。
少样本上下文学习基准评估
Otter 基于 OpenFlamingo 进行微调,OpenFlamingo 是一种专为多模态上下文学习而设计的架构。使用 MIMIC-IT 数据集进行微调后,Otter 在 COCO 字幕 (CIDEr) [27] 少样本评估(见图 6 (c))上的表现明显优于 OpenFlamingo。正如预期的那样,微调还带来了零样本评估的边际性能增益。

图 6:ChatGPT 视频理解的评估。
缺陷。虽然研究者已经迭代改进了系统消息和指令 - 响应示例,但 ChatGPT 容易出现语言幻觉,因此它可能会生成错误的响应。通常,更可靠的语言模型需要 self-instruct 数据生成。
未来工作。未来,研究者计划支持更多具体地 AI 数据集,例如 LanguageTable 和 SayCan。研究者也考虑使用更值得信赖的语言模型或生成技术来改进指令集。
以上就是280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了的详细内容,更多请关注其它相关文章!
# 这是一个
# 扶沟网站建设推广
# 贺州网站建设开发全国接单
# 东宝区网站优化推广中心
# 姑苏网站优化推广方法
# 想做个土豆网站推广
# 安顺租房网站建设管理
# 海南重庆网站建设制作
# 什么是seo帽
# 软文借势营销推广方案
# 网站的建设银行签约
# 展示了
# 数据集
# 西班牙文
# 中国
# 阿拉伯语
# 多个
# 八种
# 首个
# 多模
# 来了
# chatgpt
# 指令
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
马斯克预测:特斯拉全自动驾驶将在今年实现 对AI深度变化感到担忧
日媒:AI高效解析纳斯卡地画
V社谈AI制作游戏被ban:为确保开发者有素材所有权
马斯克WAIC2025演讲全文:AI将对人类文明产生深远影响
衡水市冀州中学机器人社团在世界机器人大赛中斩获佳绩
昇思开源社区理事会成立,基于昇思AI框架的全模态大模型“紫东.太初2.0”发布
尼康尼克尔Z 180-600mm f/5.6-6.3 VR镜头发布:12499元 拍鸟神器
RoboNeo操作教程
磐镭发布全新 GeForce RTX 4080 ARMOUR 显卡,售价为 9499 元
280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了
“风乌”气象大模型科学家团队:用AI预报极端天气未来不是梦!
iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了
亚太地区 70% 的企业高管正探索生成式 AI 应用或已经进行投资
借助ChatGPT快速上手ElasticSearch dsl
日新月异,脑机接口技术都有哪些新应用?
人工智能“Aria”现身 Opera浏览器100版本更新:新功能“标签岛”
“智能体动作生成技术”现身WAIC:游戏AI技术为机器人科创注入新动力
人工智能在重症监护室的未来
DeepMind推惊世排序算法,C++库忙更新!
外科医生的智能助手,“机器人手术”得到补充商业医保覆盖
创新科学家成功研发FAST激光靶标维护机器人
微软 GitHub Copilot 编程助手被投诉:换口吻改写公共代码来躲版权
中美陷入囚徒困境,人工智能变得不可控?可参考核不扩散条约规范
如何获得元宇宙的第一个属于自己的空间
PS AI修图免费平替来了!Stability AI又放大招,核弹级更新一键扩图
OpenAI更新GPT-4等模型,新增API函数调用,价格最高降75%
软银、淡马锡、沙特阿美突击入股,“协作机器人第一股”节卡股份:强敌环伺,持续失血是常态
实现人工智能和物联网的协同运作
华为发布大模型时代AI存储新品
“痴迷”元宇宙,魔珐科技想做什么?
将上下文长度扩展到256k,无限上下文版本的LongLLaMA来了?
支持跨语言、人声狗吠互换,仅利用最近邻的简单语音转换模型有多神奇
百度举办AIGC创作沙龙,现场传授AI绘画“咒语”技巧
杀入生成式AI的亚马逊云科技,能否再次生成未来?
官宣!爱康AI未来之夜三大亮点提前剧透!
轻量级的深度学习框架Tinygrad
OpenOOD更新v1.5:全面、精确的分布外检测代码库及测试平台,支持在线排行榜、一键测试
日本演员工会提出AI立法建议 要求建立“声音肖像权”
AI证件照生成器:实际测试中AI软件展现了绝无仅有的强大效能
金山办公宣布与英伟达团队合作,加速WPS AI服务
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
Adobe旗下Illustrator引入生成式AI工具Firefly
谷歌将使用公开信息训练 AI 模型,构建更强大的自家产品
人工智能驱动艺术,打开达利的超现实想象
人工智能进入绿植界,智能庭院市场初具规模
家电行业观察:AI加持下,全屋智能将成为智能家电未来?
技术如何使人变得懒惰?
看了天美对AI的布局,我感觉它想得是真明白
新华三集团总裁兼首席执行官于英涛:人工智能时代需要想象力,更需要精耕务实
AI+游戏首度大范围公布实际应用成果,AI全面来临还有多远?
2023-06-13

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
