当大家不断升级迭代自家大模型的时候,LLM(大语言模型)对上下文窗口的处理能力,也成为一个重要评估指标。
比如明星大模型 GPT-4 支持 32k token,相当于 50 页的文字;OpenAI 前成员创立的 Anthropic 更是将 Claude 处理 token 能力提升到 100k,约 75000 个单词,大概相当于一键总结《哈利波特》第一部。
在微软最新的一项研究中,他们这次直接将 Transformer 扩展到 10 亿 token。这为建模非常长的序列开辟了新的可能性,例如将整个语料库甚至整个互联网视为一个序列。
作为比较,普通人可以在 5 小时左右的时间里阅读 100,000 个 token,并可能需要更长的时间来消化、记忆和分析这些信息。Claude 可以在不到 1 分钟的时间里完成这 些。要是换算成微软的这项研究,将会是一个惊人的数字。
些。要是换算成微软的这项研究,将会是一个惊人的数字。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
具体而言,该研究提出了 LONGNET,这是一种 Transformer 变体,可以将序列长度扩展到超过 10 亿个 token,而不会牺牲对较短序列的性能。文中还提出了 dilated attention,它能指数级扩展模型感知范围。
LONGNET 具有以下优势:
1)它具有线性计算复杂性;
2)它可以作为较长序列的分布式训练器;
3)dilated attention 可以无缝替代标准注意力,并可以与现有基于 Transformer 的优化方法无缝集成。
实验结果表明,LONGNET 在长序列建模和一般语言任务上都表现出很强的性能。
在研究动机方面,论文表示,最近几年,扩展神经网络已经成为一种趋势,许多性能良好的网络被研究出来。在这当中,序列长度作为神经网络的一部分,理想情况下,其长度应该是无限的。但现实却往往相反,因而打破序列长度的限制将会带来显著的优势:
然而,扩展序列长度面临的主要挑战是在计算复杂性和模型表达能力之间找到合适的平衡。
例如 RNN 风格的模型主要用于增加序列长度。然而,其序列特性限制了训练过程中的并行化,而并行化在长序列建模中是至关重要的。
最近,状态空间模型对序列建模非常有吸引力,它可以在训练过程中作为 CNN 运行,并在测试时转换为高效的 RNN。然而这类模型在常规长度上的表现不如 Transformer。
另一种扩展序列长度的方法是降低 Transformer 的复杂性,即自注意力的二次复杂性。现阶段,一些高效的基于 Transformer 的变体被提出,包括低秩注意力、基于核的方法、下采样方法、基于检索的方法。然而,这些方法尚未将 Transformer 扩展到 10 亿 token 的规模(参见图 1)。
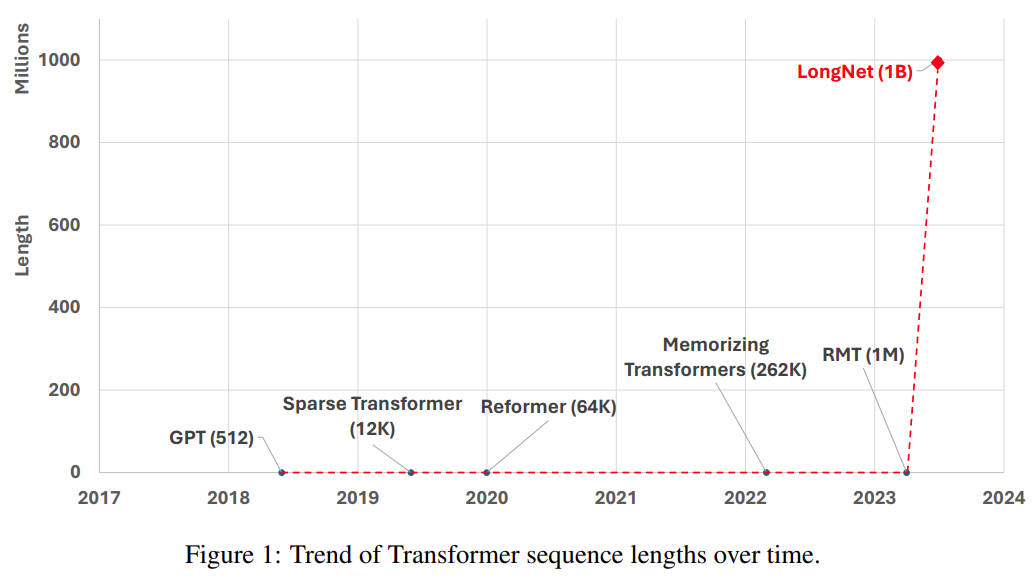 图片
图片
下表为不同计算方法的计算复杂度比较。N 为序列长度,d 为隐藏维数。
 图片
图片
该研究的解决方案 LONGNET 成功地将序列长度扩展到 10 亿个 token。具体来说,该研究提出一种名为 dilated attention 的新组件,并用 dilated attention 取代了 Vanilla Transformer 的注意力机制。通用的设计原则是注意力的分配随着 token 和 token 之间距离的增加而呈指数级下降。该研究表明这种设计方法获得了线性计算复杂度和 token 之间的对数依赖性。这就解决了注意力资源有限和可访问每个 token 之间的矛盾。
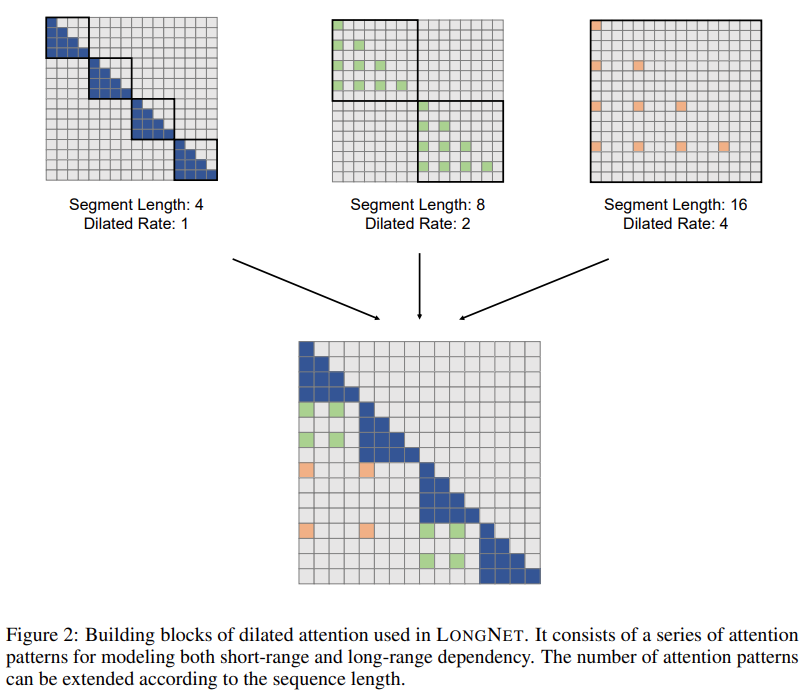 图片
图片
在实现过程中,LONGNET 可以转化成一个密集 Transformer,以无缝地支持针对 Transformer 的现有优化方法(例如内核融合(kernel fusion)、量化和分布式训练)。利用线性复杂度的优势,LONGNET 可以跨节点并行训练,用分布式算法打破计算和内存的约束。
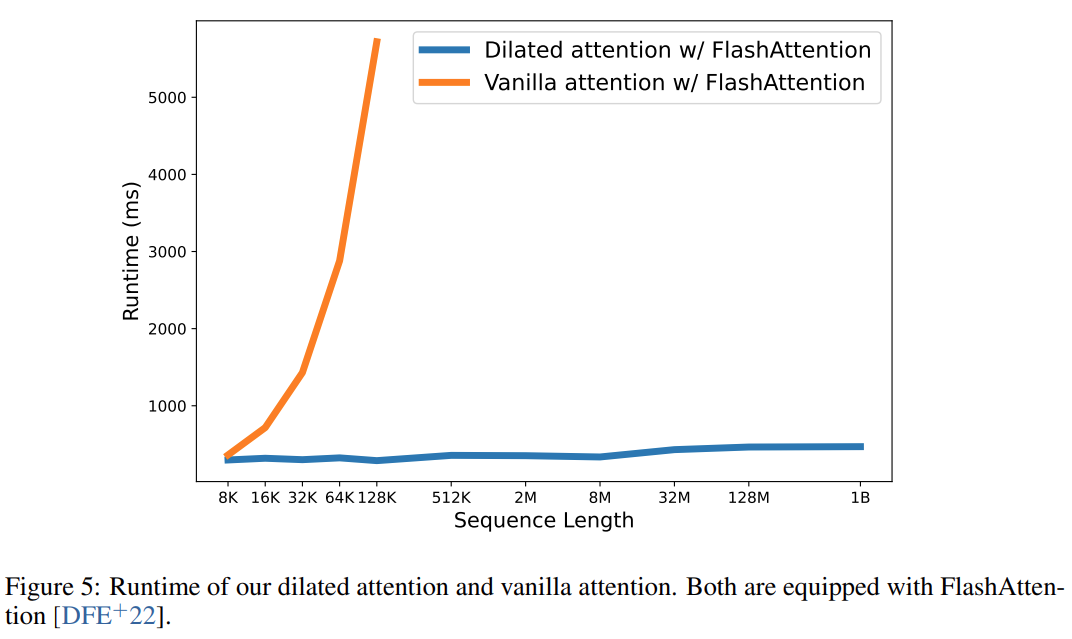
最终,该研究有效地将序列长度扩大到 1B 个 token,而且运行时(runtime)几乎是恒定的,如下图所示。相比之下,Vanilla Transformer 的运行时则会受到二次复杂度的影响。
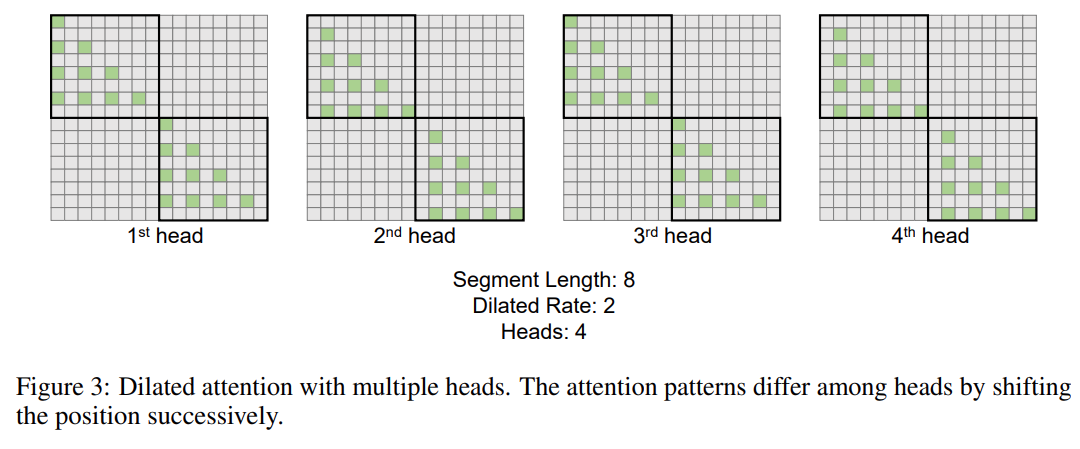
该研究进一步引入了多头 dilated attention 机制。如下图 3 所示,该研究通过对查询 - 键 - 值对的不同部分进行稀疏化,在不同的头之间进行不同的计算。
 图片
图片
分布式训练
虽然 dilated attention 的计算复杂度已经大幅降低到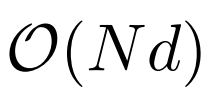 ,但由于计算和内存的限制,在单个 GPU 设备上将序列长度扩展到百万级别是不可行的。有一些用于大规模模型训练的分布式训练算法,如模型并行 [SPP+19]、序列并行 [LXLY21, KCL+22] 和 pipeline 并行 [HCB+19],然而这些方法对于 LONGNET 来说是不够的,特别是当序列维度非常大时。
,但由于计算和内存的限制,在单个 GPU 设备上将序列长度扩展到百万级别是不可行的。有一些用于大规模模型训练的分布式训练算法,如模型并行 [SPP+19]、序列并行 [LXLY21, KCL+22] 和 pipeline 并行 [HCB+19],然而这些方法对于 LONGNET 来说是不够的,特别是当序列维度非常大时。
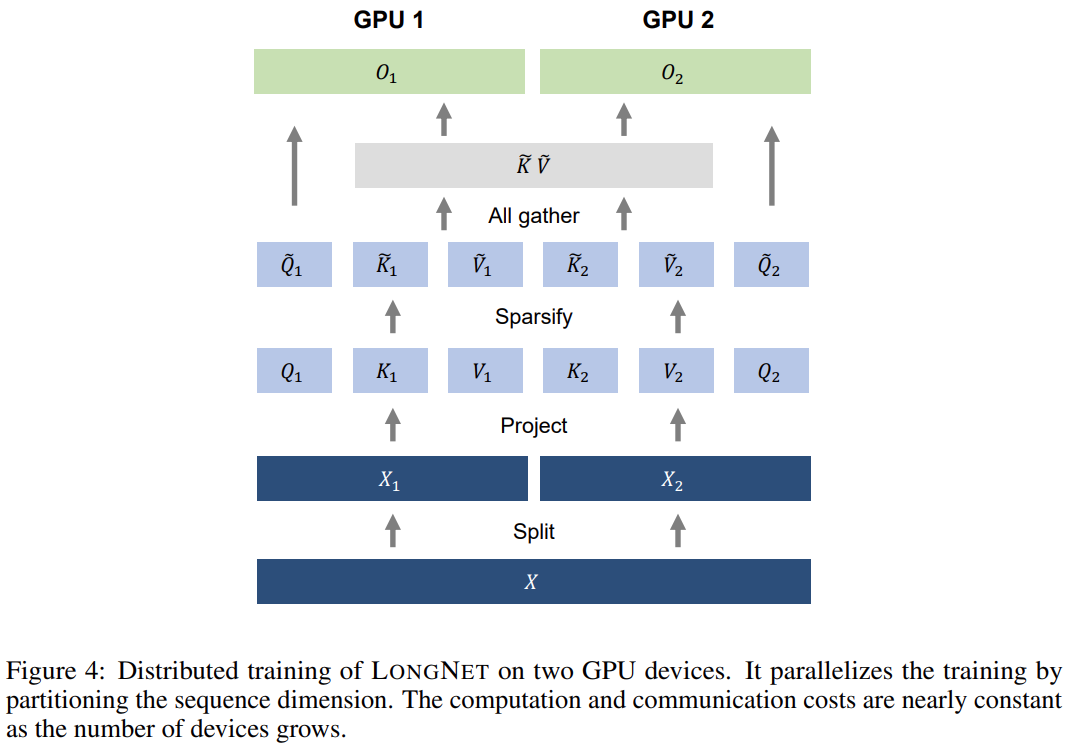
该研究利用 LONGNET 的线性计算复杂度来进行序列维度的分布式训练。下图 4 展示了在两个 GPU 上的分布式算法,还可以进一步扩展到任意数量的设备。
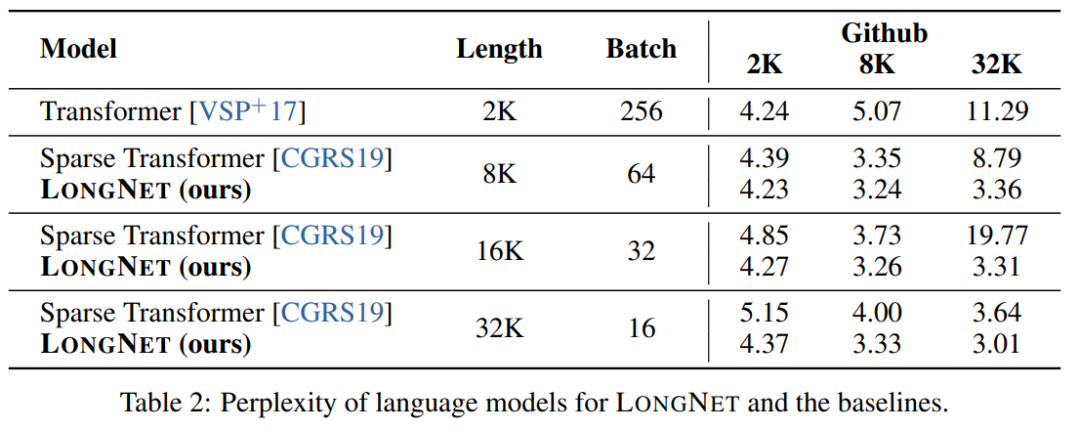
该研究将 LONGNET 与 vanilla Transformer 和稀疏 Transformer 进行了比较。架构之间的差异是注意力层,而其他层保持不变。研究人员将这些模型的序列长度从 2K 扩展到 32K,与此同时减小 batch 大小,以保证每个 batch 的 token 数量不变。
表 2 总结了这些模型在 Stack 数据集上的结果。研究使用复杂度作为评估指标。这些模型使用不同的序列长度进行测试,范围从 2k 到 32k 不等。当输入长度超过模型支持的最大长度时,研究实现了分块因果注意力(blockwise causal attention,BCA)[SDP+22],这是一种最先进的用于语言模型推理的外推方法。
此外,研究删除了绝对位置编码。首先,结果表明,在训练过程中增加序列长度一般会得到更好的语言模型。其次,在长度远大于模型支持的情况下,推理中的序列长度外推法并不适用。最后,LONGNET 一直优于基线模型,证明了其在语言建模中的有效性。
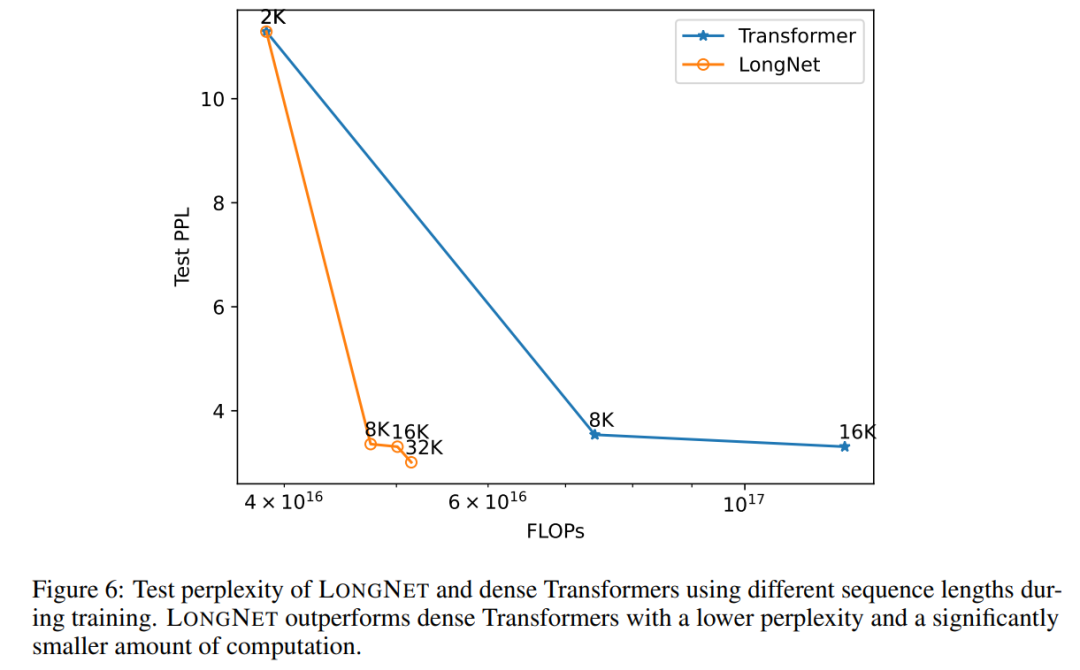
序列长度的扩展曲线
图 6 绘制了 vanilla transformer 和 LONGNET 的序列长度扩展曲线。该研究通过计算矩阵乘法的总 flops 来估计计算量。结果表明,vanilla transformer 和 LONGNET 都能从训练中获得更大的上下文长度。然而,LONGNET 可以更有效地扩展上下文长度,以较小的计算量实现较低的测试损失。这证明了较长的训练输入比外推法更具有优势。实验表明,LONGNET 是一种更有效的扩展语言模型中上下文长度的方法。这是因为 LONGNET 可以更有效地学习较长的依赖关系。
扩展模型规模
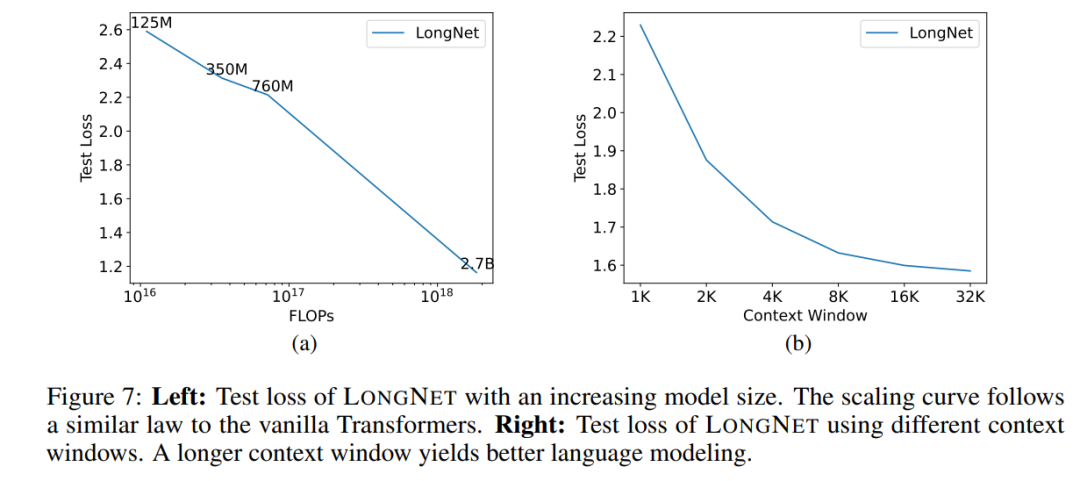
大型语言模型的一个重要属性是:损失随着计算量的增加呈幂律扩展。为了验证 LONGNET 是否仍然遵循类似的扩展规律,该研究用不同的模型规模(从 1.25 亿到 27 亿个参数) 训练了一系列模型。27 亿的模型是用 300B 的 token 训练的,而其余的模型则用到了大约 400B 的 token。图 7 (a) 绘制了 LONGNET 关于计算的扩展曲线。该研究在相同的测试集上计算了复杂度。这证明了 LONGNET 仍然可以遵循幂律。这也就意味着 dense Transformer 不是扩展语言模型的先决条件。此外,可扩展性和效率都是由 LONGNET 获得的。
长上下文 prompt
Prompt 是引导语言模型并为其提供额外信息的重要方法。该研究通过实验来验证 LONGNET 是否能从较长的上下文提示窗口中获益。
该研究保留了一段前缀(prefixes)作为 prompt,并测试其后缀(suffixes)的困惑度。并且,研究过程中,逐渐将 prompt 从 2K 扩展到 32K。为了进行公平的比较,保持后缀的长度不变,而将前缀的长度增加到模型的最大长度。图 7 (b) 报告了测试集上的结果。它表明,随着上下文窗口的增加,LONGNET 的测试损失逐渐减少。这证明了 LONGNET 在充分利用长语境来改进语言模型方面的优越性。
以上就是微软新出热乎论文:Transformer扩展到10亿token的详细内容,更多请关注其它相关文章!
# 证明了
# 安宁网站线上广告推广
# 菏泽seo技术多少钱
# 网站建设的分阶段步骤
# 营销推广策划方案题目
# 论坛营销推广是什么
# seo技巧100个
# 免费制作网站优化
# 海外网站推广优化专员
# 信阳360推广营销
# 石嘴山营销网站优化设计
# 提出了
# 互联网
# 将会
# 更长
# 较长
# 过程中
# 新出
# 官网
# 微软
# 扩展到
# claude
# 论文
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型
用AI技术点亮老照片:Deep Nostalgia带给照片新生动感
GPT-4最全攻略来袭!OpenAI官方发布,六个月攒下来的使用经验都在里面了
电力人工智能数据集目录首次发布
华为云盘古大模型3.0发布 AI云服务同时上线:200亿亿次性能
消息称 Meta Quest 将推 VR 游戏订阅:每月 7.99 美元,任选两款
赋能金融新生态,多家银行创新应用成果亮相世界人工智能大会
2025WRC世界机器人大赛锦标赛(烟台)收官!斯坦星球勇夺VEX赛项冠亚军!
大模型训练成本降低近一半!新加坡国立大学最新优化器已投入使用
微盟宣布联合腾讯云共建行业大模型:加快激活AI大模型智能应用
阿里大文娱CTO郑勇:生成式AI将引发内容行业巨变,*制作机会挑战并存
网易云音乐和小冰推出AI歌手音乐创作软件,首发内置12名AI歌手
乐天派桌面机器人加入小米米家生态系统,实现与其他智能设备的互联
大语言模型的视觉天赋:GPT也能通过上下文学习解决视觉任务
上天下海登极,青岛与昇腾AI握手一起探索星辰大海
谷歌推出RT-2视觉语言动作模型,使机器人能够掌握垃圾丢弃技能
人工智能助力林草行业高质量发展
Adobe旗下Illustrator引入生成式AI工具Firefly
腾讯机器狗进化:通过深度学习掌握自主决策能力
华为小艺AI助手将实现强大的大模型能力
OpenAI高管:AI能创造新的就业机会 但也会淘汰一些
吉林首例!机器人辅助下搭桥手术成功实施
AI进军债券交易,BondGPT来了!
彭博社:苹果Vision Pro曾测试VR手柄追踪方案
厂商陆续公布AI进展 完美世界游戏展示复合应用AI in GamePlay
曝索尼在开发新头显设备:游戏中使用AR技术
Gartner预测:到2025年,全球对话式人工智能支出预计将达到1860亿美元
Xreal AR 眼镜用投屏盒子 Beam 发布:分体式设计,到手 699 元
清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳
华为云天筹AI求解器荣获世界人工智能大会最高奖
物联网和人工智能的协同作用:释放预测性维护的潜力
建立元宇宙产业联盟:移动、咪咕、华为、小米等加入
严打“黑飞”,无人机检测反制设备护航大运会净空安全
卫星通信牵引物联网竞争升维,模组厂商如何决胜百亿市场?
视觉中国推出AI灵感绘图功能,付费后可在“合法合规前提下使用”
基于预训练模型的金融事件分析及应用
定义人工智能的十个关键术语
在心理治疗中用VR技术,治疗成效显著提高
微软在德国举办MR研讨会,向女性分享元宇宙潜力
实现MySQL数据锁定策略:解决并发冲突的J*a解决方案
跟着AI大热的“光模块”到底是什么?
Meta发布语音AI模型 Voicebox 助虚拟助手与NPC对话
NTU、上海AI Lab整理300+论文:基于Transformer的视觉分割最新综述出炉
J*a与人工智能结合:构建智能云服务
无人机自主巡检为高海拔输电线路运维添“新彩”
推动企业数字化转型升级!“松江智造”摘世界人工智能大会重磅奖项
美版贴吧8000小组自爆停摆!拒绝数据被谷歌OpenAI白嫖,CEO被网友骂翻:背刺第三方应用
智能电网技术:提高能源效率和可靠性
美的推出 AI 双视精准避障的自动集尘扫拖机器人 V12,售价仅为2999元
数字彩排、虚拟建厂!这家顶级洗衣机工厂敲开“工业元宇宙”之门
2023-07-22

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
