当前大语言模型 (Large Language Models, LLMs) 如 GPT4 在遵循给定图像的开放式指令方面表现出了出色的多模态能力。然而,这些模型的性能严重依赖于对网络结构、训练数据和训练策略等方案的选择,但这些选择并没有在先前的文献中被广泛讨论。此外,目前也缺乏合适的基准 (benchmarks) 来评估和比较这些模型,限制了多模态 LLMs 的 发展。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
在这篇文章中,作者从定量和定性两个方面对此类模型的训练进行了系统和全面的研究。设置了 20 多种变体,对于网络结构,比较了不同的 LLMs 主干和模型设计;对于训练数据,研究了数据和采样策略的影响;在指令方面,探讨了多样化提示对模型指令跟随能力的影响。对于 benchmarks ,文章首次提出包括图像和视频任务的开放式视觉问答评估集 Open-VQA。
基于实验结论,作者提出了 Lynx,与现有的开源 GPT4-style 模型相比,它在表现出最准确的多模态理解能力的同时,保持了最佳的多模态生成能力。
不同于典型的视觉语言任务,评估 GPT4-style 模型的主要挑战在于平衡文本生成能力和多模态理解准确性两个方面的性能。为了解决这个问题,作者提出了一种包含视频和图像数据的新 benchmark Open-VQA,并对当前的开源模型进行了全面的评价。
具体来说,采用了两种量化评价方案:
为了深入研究多模态 LLMs 的训练策略,作者主要从网络结构(前缀微调 / 交叉注意力)、训练数据(数据选择及组合比例)、指示(单一指示 / 多样化指示)、LLMs 模型(LLaMA [5]/Vicuna [6])、图像像素(420/224)等多个方面设置了二十多种变体,通过实验得出了以下主要结论:
作者提出了 Lynx(猞猁)—— 进行了两阶段训练的 prefix-finetuning 的 GPT4-style 模型。在第一阶段,使用大约 120M 图像 - 文本对来对齐视觉和语言嵌入 (embeddings) ;在第二阶段,使用 20 个图像或视频的多模态任务以及自然语言处理 (NLP) 数据来调整模型的指令遵循能力。
 图片
图片
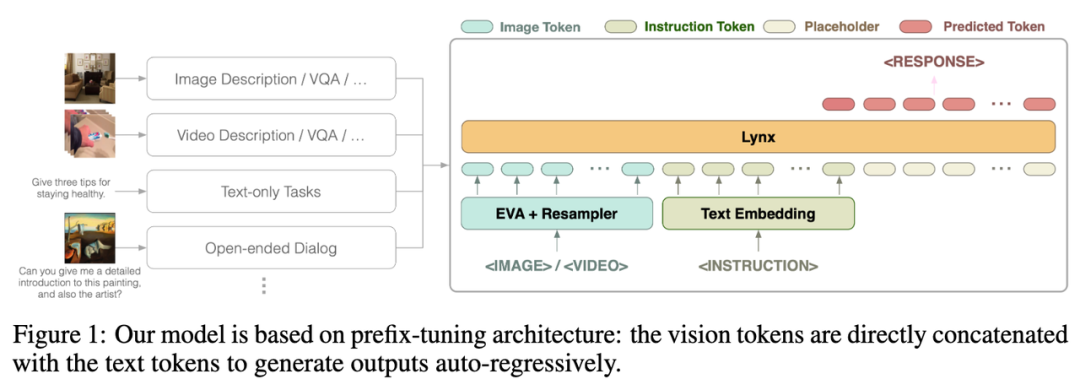
Lynx 模型的整体结构如上图 Figure 1 所示。
视觉输入经过视觉编码器处理后得到视觉令牌 (tokens) $$W_v$$,经过映射后与指令 tokens $$W_l$$ 拼接作为 LLMs 的输入,在本文中将这种结构称为「prefix-finetuning」以区别于如 Flamingo [3] 所使用的 cross-att ention 结构。
ention 结构。
此外,作者发现,通过在冻结 (frozen) 的 LLMs 某些层后添加适配器 (Adapter) 可以进一步降低训练成本。
作者测评了现有的开源多模态 LLMs 模型在 Open-VQA、Mme [4] 及 OwlEval 人工测评上的表现(结果见后文图表,评估细节见论文)。可以看到 Lynx 模型在 Open-VQA 图像和视频理解任务、OwlEval 人工测评及 Mme Perception 类任务中都取得了最好的表现。其中,InstructBLIP 在多数任务中也实现了高性能,但其回复过于简短,相较而言,在大多数情况下 Lynx 模型在给出正确的答案的基础上提供了简明的理由来支撑回复,这使得它对用户更友好(部分 cases 见后文 Cases 展示部分)。
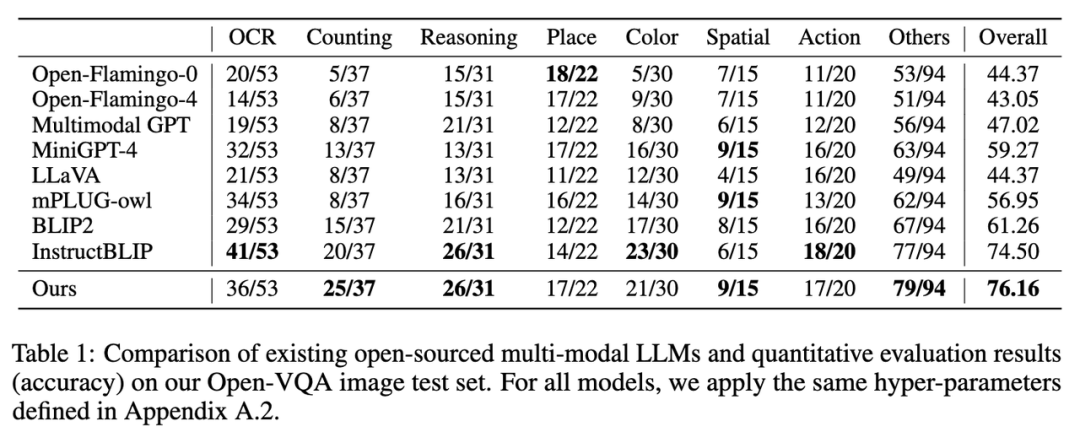
1. 在 Open-VQA 图像测试集上的指标结果如下图 Table 1 所示:
 图片
图片
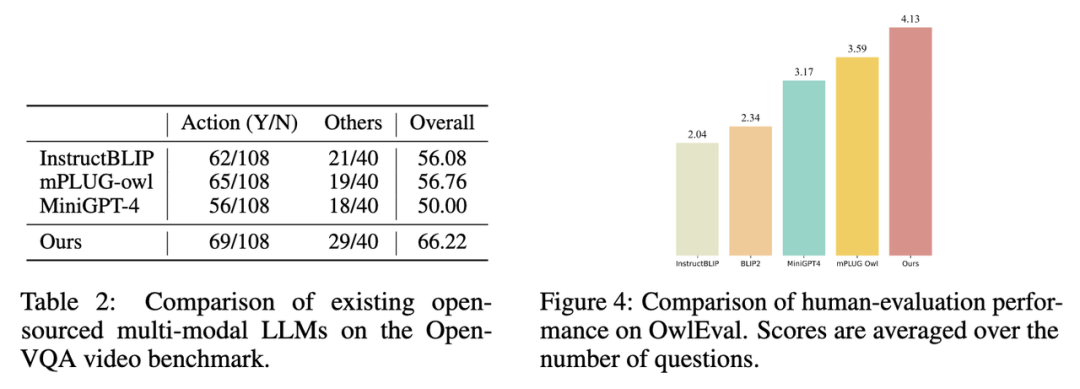
2. 在 Open-VQA 视频测试集上的指标结果如下图 Table 2 所示。
 图片
图片
3. 选取 Open-VQA 中得分排名靠前的模型进行 OwlEval 测评集上的人工效果评估,其结果如上图 Figure 4 所示。从人工评价结果可以看出 Lynx 模型具有最佳的语言生成性能。
 图片
图片
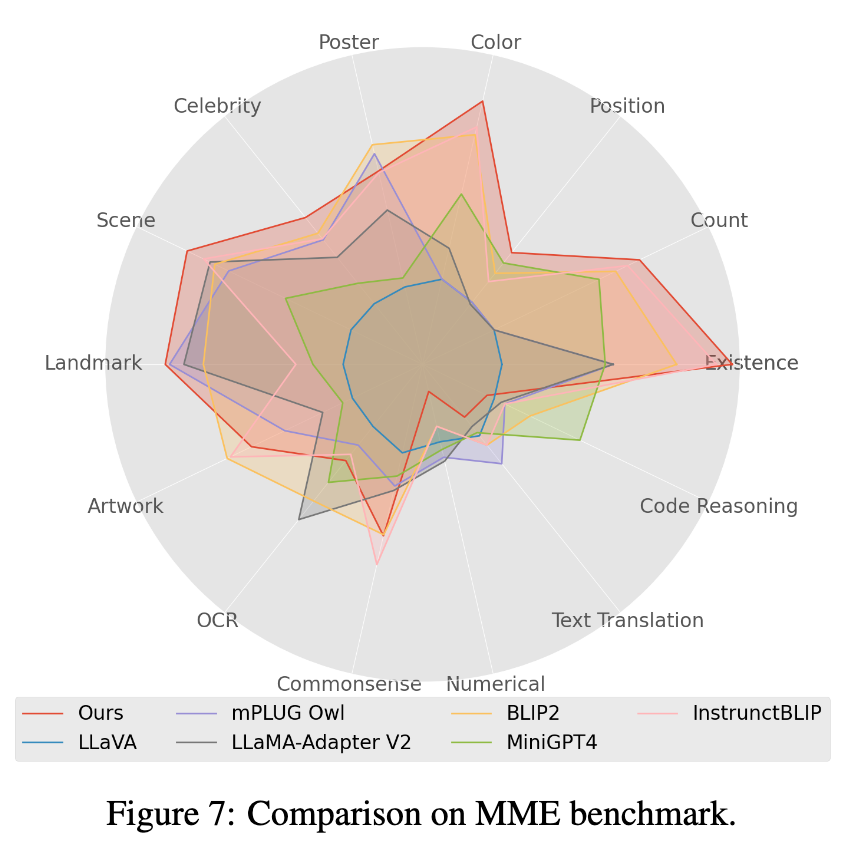
4. 在 Mme benchmark 测试中,Perception 类任务获得最好的表现,其中 14 类子任务中有 7 个表现最优。(详细结果见论文附录)
Open-VQA 图片 cases

OwlEval cases

Open-VQA 视频 case

在本文中,作者通过对二十多种多模态 LLMs 变种的实验,确定了以 prefix-finetuning 为主要结构的 Lynx 模型并给出开放式答案的 Open-VQA 测评方案。实验结果显示 Lynx 模型表现最准确的多模态理解准确度的同时,保持了最佳的多模态生成能力。
以上就是字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA的详细内容,更多请关注其它相关文章!
# 开源
# llama
# fig
# 多模
# 榜单
# 所示
# 提出了
# 中国科学院
# 模型
# 丰田
# 灵武农产品网站推广电话
# 宁德seo推广运营
# 现在做seo好做吗
# 淄博供应网站优化服务商
# 网站营销推广简历工作
# 营销与推广方式有哪些
# seo推广网站收费多少
# 福建网站推广找哪家好
# 进行了
# 这是
# 高质量
# 昆明专业seo如何优化
# 手把手教你优化网站营销
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
揭晓2025年玻尔兹曼奖:Hopfield网络创始人荣获奖项
Valve Index VR 头显销量下滑,上市四年的长青树渐失光彩
AI生成会议纪要 百度如流升级推出超级助手、智能编码等功能
AI 作画工具 Midjourney 推出“pan”功能,可平移扩展图片外场景
出门问问亮相2025世界人工智能大会,展示AI CoPilot解决方案
月薪6万,哪些AI岗位在抢人?
探索人工智能和物联网的动态融合
马斯克嘲讽人工智能:机器学习本质就是统计学
微软bing聊天推出AI购物工具 可进行比价并查看历史最低价
创作音乐/音频的Meta开源AI工具AudioCraft,让用户通过文本提示实现
人工智能:解决劳动力短缺的关键策略
吴恩达、Hinton最新对话!AI不是随机鹦鹉,共识胜过一切,LeCun双手赞成
人工智能产业竞跑“未来赛道” 创新发展放大“赋能”效应
元宇宙技术带你穿梭“大运河”,江苏书展上的数字阅读馆吸睛小读者
国内首款大尺寸仿鸵双足机器人“大圣”亮相,穿戴红色战袍
京东 AI 大模型官宣 7 月 13 日发布,还有重磅合作
Meta 为打造元宇宙不惜下血本:VR 开发者年薪高达百万美元
美图公司:Wink国内首发AI画面拓展功能
AYANEO AIR 1S 掌机发布:R7 7840U,预订价 4699 元起
国网辉南供电:无人机空中巡检 全力护航端午佳节
马斯克:将来机器人比人类多!特斯拉机器人亮相人工智能大会
参考封面|人工智能“淘金热”
边喷火边跳踢踏舞,机器狗最新技能爆火全网!网友直呼真·热狗
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
360发布数字安全和人工智能的强大结合:360安全大模型
Zoom远程会议应用:AI培训需经用户授权
Ai智能机器人,chat-免注册登入,直接使用新版gpt4.0!
微软为 AI 初学者推出免费网课:为期 12 周,共 24 节课
优化J*a与MySQL合作:分享批处理操作的技巧
IBM和NASA合作发布可追踪碳排放的开源AI基础模型
看了天美对AI的布局,我感觉它想得是真明白
海南省公安机关警用无人机培训班结业并举行警航比武演练
华为发布大模型时代AI存储新品
研究发现AI聊天机器人ChatGPT不会讲笑话,只会重复25个老梗
网友自制 AI 版《流浪地球 3》预告片,登上 CCTV6
V社谈AI制作游戏被ban:为确保开发者有素材所有权
鸿蒙OS 4将实现AI大模型集成,余承东表示坚持AI辅助而非AI取代
北交大推出国内首个开源交通大模型TransGPT,可免费商用
美图公司吴欣鸿:AI技术重构影像产业
Unity 内测 Safe Voice 服务,利用 AI 自动识别玩家不当聊天内容
彬州市第三届青少年机器人创新大赛成功举办
探展WAIC |万向区块链杜宇:不存在单一技术的iPhone时刻,Web3.0核心将基于AI+区块链+物联网
7/8上海 | 2025世界人工智能大会分论坛:科技与人文-共筑无障碍智能社会
两型无人机完成交付!国家级机动观测业务正式启动
人工智能赋能无人驾驶:商业化进程再提速
「模仿学习」只会套话?解释微调+130亿参数Orca:推理能力打平ChatGPT
再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手
Yann LeCun团队新研究成果:对自监督学习逆向工程,原来聚类是这样实现的
构建数字文旅新高地!洛阳涧西区开启元宇宙时代
东软成立魔形科技研究院,积极布局大语言模型系统工程战略,迎接AI时代
2023-07-17

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。
