本文介绍了Swin Transformer模型的代码复现情况。作者完成了BackBone代码迁移,ImageNet 1k预训练模型可用且精度对齐,模型代码和ImageNet 22k预训练模型将更新到PPIM项目。文中展示了模型组网代码,包括窗口划分、注意力机制等模块,还提供了预设模型及精度验证结果,Swin-T在验证集上top1准确率达81.19%。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
官方项目:microsoft/Swin-Transformer
才疏学浅,只会写写代码,就不班门弄斧解读这论文了
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情

具体详解可以参考 @长风破浪会有时 大佬发布的项目 Swin Transformer,之前大佬写的 RepVGG 和 ReXNet 模型解析太强了
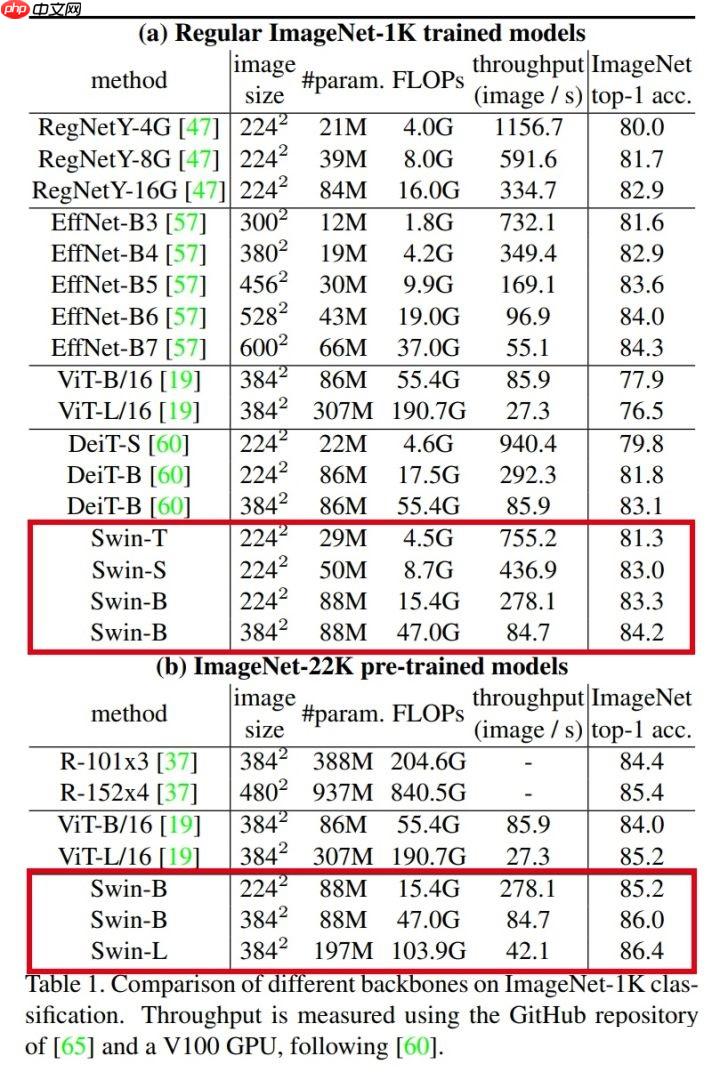
模型精度细节:
# 安装 PPIM!pip install ppim
import numpy as npimport paddleimport paddle.nn as nnimport paddle.vision.transforms as Tfrom ppim.models.vit import Mlpfrom ppim.models.common import to_2tuplefrom ppim.models.common import DropPath, Identityfrom ppim.models.common import trunc_normal_, zeros_, ones_
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.reshape((B, H // window_size, window_size,
W // window_size, window_size, C))
windows = x.transpose((0, 1, 3, 2, 4, 5)).reshape(
(-1, window_size, window_size, C)) return windowsdef window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.reshape(
(B, H // window_size, W // window_size, window_size, window_size, -1))
x = x.transpose((0, 1, 3, 2, 4, 5)).reshape((B, H, W, -1)) return xclass WindowAttention(nn.Layer):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = self.create_parameter(
shape=((2 * window_size[0] - 1) *
(2 * window_size[1] - 1), num_heads),
default_initializer=zeros_
) # 2*Wh-1 * 2*Ww-1, nH
self.add_parameter("relative_position_bias_table",
self.relative_position_bias_table) # get pair-wise relative position index for each token inside the window
coords_h = paddle.arange(self.window_size[0])
coords_w = paddle.arange(self.window_size[1])
coords = paddle.stack(paddle.meshgrid(
[coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = paddle.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten.unsqueeze(-1) - \
coords_flatten.unsqueeze(1) # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.transpose(
(1, 2, 0)) # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - \ 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index",
relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table)
self.softmax = nn.Softmax(axis=-1) def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape((B_, N, 3, self.num_heads, C //
self.num_heads)).transpose((2, 0, 3, 1, 4))
q, k, v = qkv[0], qkv[1], qkv[2]
q = q * self.scale
attn = q.matmul(k.transpose((0, 1, 3, 2)))
relative_position_bias = paddle.index_select(
self.relative_position_bias_table,
self.relative_position_index.reshape((-1,)),
axis=0).reshape(
(self.window_size[0] * self.window_size[1],
self.window_size[0] * self.window_size[1], -1))
relative_position_bias = relative_position_bias.transpose((2, 0, 1))
attn = attn + relative_position_bias.unsqueeze(0) if mask is not None:
nW = mask.shape[0]
attn = attn.reshape(
(B_ // nW, nW, self.num_heads, N, N)
) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.reshape((-1, self.num_heads, N, N))
attn = self.softmax(attn) else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((B_, N, C))
x = self.proj(x)
x = self.proj_drop(x) return xclass SwinTransformerBlock(nn.Layer):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Layer, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio if min(self.input_resolution) <= self.window_size: # if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution) assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop) if self.shift_size > 0: # calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = paddle.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size), slice(-self.window_size, -self.shift_size), slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size), slice(-self.window_size, -self.shift_size), slice(-self.shift_size, None))
cnt = 0
for h in h_slices: for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
# nW, window_size, window_size, 1
mask_windows = window_partition(img_mask, self.window_size)
mask_windows = mask_windows.reshape((-1,
self.window_size * self.window_size))
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
_h = paddle.full_like(attn_mask, -100.0, dtype='float32')
_z = paddle.full_like(attn_mask, 0.0, dtype='float32')
attn_mask = paddle.where(attn_mask != 0, _h, _z) else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask) def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.reshape((B, H, W, C)) # cyclic shift
if self.shift_size > 0:
shifted_x = paddle.roll(
x, shifts=(-self.shift_size, -self.shift_size), axis=(1, 2)) else:
shifted_x = x # partition windows
# nW*B, window_size, window_size, C
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size*window_size, C
x_windows = x_windows.reshape(
(-1, self.window_size * self.window_size, C)) # W-MSA/SW-MSA
# nW*B, window_size*window_size, C
attn_windows = self.attn(x_windows, mask=self.attn_mask) # merge windows
attn_windows = attn_windows.reshape(
(-1, self.window_size, self.window_size, C))
shifted_x = window_reverse(
attn_windows, self.window_size, H, W) # B H' W' C
# reverse cycli c shift
if self.shift_size > 0:
x = paddle.roll(shifted_x, shifts=(
self.shift_size, self.shift_size), axis=(1, 2)) else:
x = shifted_x
x = x.reshape((B, H * W, C)) # FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x))) return xclass PatchMerging(nn.Layer):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias_attr=False)
self.norm = norm_layer(4 * dim) def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.reshape((B, H, W, C))
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = paddle.concat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.reshape((B, -1, 4 * C)) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x) return xclass BasicLayer(nn.Layer):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Layer | None, optional): Downsample layer at the end of the layer. Default: None
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth # build blocks
self.blocks = nn.LayerList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (
i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(
drop_path, np.ndarray) else drop_path,
norm_layer=norm_layer) for i in range(depth)]) # patch merging layer
if downsample is not None:
self.downsample = downsample(
input_resolution, dim=dim, norm_layer=norm_layer) else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
x = blk(x) if self.downsample is not None:
x = self.downsample(x) return xclass PatchEmbed(nn.Layer):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Layer, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] //
patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2D(in_chans, embed_dim,
kernel_size=patch_size, stride=patch_size) if norm_layer is not None:
self.norm = norm_layer(embed_dim) else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape # FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose((0, 2, 1)) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x) return xclass SwinTransformer(nn.Layer):
r""" Swin Transformer
A Paddle impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
class_dim (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Layer): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
class_dim=1000, with_pool=True, **kwargs):
super().__init__()
self.class_dim = class_dim
self.with_pool = with_pool
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio # split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution # absolute position embedding
if self.ape:
self.absolute_pos_embed = self.create_parameter(
shape=(1, num_patches, embed_dim),
default_initializer=zeros_
)
self.add_parameter("absolute_pos_embed", self.absolute_pos_embed)
trunc_normal_(self.absolute_pos_embed)
self.pos_drop = nn.Dropout(p=drop_rate) # stochastic depth
dpr = np.linspace(0, drop_path_rate, sum(depths)) # build layers
self.layers = nn.LayerList() for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(
depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (
i_layer < self.num_layers - 1) else None
)
self.layers.append(layer)
self.norm = norm_layer(self.num_features) if with_pool:
self.*gpool = nn.AdaptiveAvgPool1D(1)
if class_dim > 0:
self.head = nn.Linear(self.num_features, class_dim)
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_features(self, x):
x = self.patch_embed(x) if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x) for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
return x.transpose((0, 2, 1)) # B C 1
def forward(self, x):
x = self.forward_features(x) if self.with_pool:
x = self.*gpool(x)
if self.class_dim > 0:
x = paddle.flatten(x, 1)
x = self.head(x) return x
c shift
if self.shift_size > 0:
x = paddle.roll(shifted_x, shifts=(
self.shift_size, self.shift_size), axis=(1, 2)) else:
x = shifted_x
x = x.reshape((B, H * W, C)) # FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x))) return xclass PatchMerging(nn.Layer):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias_attr=False)
self.norm = norm_layer(4 * dim) def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.reshape((B, H, W, C))
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = paddle.concat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.reshape((B, -1, 4 * C)) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x) return xclass BasicLayer(nn.Layer):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Layer | None, optional): Downsample layer at the end of the layer. Default: None
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth # build blocks
self.blocks = nn.LayerList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (
i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(
drop_path, np.ndarray) else drop_path,
norm_layer=norm_layer) for i in range(depth)]) # patch merging layer
if downsample is not None:
self.downsample = downsample(
input_resolution, dim=dim, norm_layer=norm_layer) else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
x = blk(x) if self.downsample is not None:
x = self.downsample(x) return xclass PatchEmbed(nn.Layer):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Layer, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] //
patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2D(in_chans, embed_dim,
kernel_size=patch_size, stride=patch_size) if norm_layer is not None:
self.norm = norm_layer(embed_dim) else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape # FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose((0, 2, 1)) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x) return xclass SwinTransformer(nn.Layer):
r""" Swin Transformer
A Paddle impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
class_dim (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Layer): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
class_dim=1000, with_pool=True, **kwargs):
super().__init__()
self.class_dim = class_dim
self.with_pool = with_pool
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio # split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution # absolute position embedding
if self.ape:
self.absolute_pos_embed = self.create_parameter(
shape=(1, num_patches, embed_dim),
default_initializer=zeros_
)
self.add_parameter("absolute_pos_embed", self.absolute_pos_embed)
trunc_normal_(self.absolute_pos_embed)
self.pos_drop = nn.Dropout(p=drop_rate) # stochastic depth
dpr = np.linspace(0, drop_path_rate, sum(depths)) # build layers
self.layers = nn.LayerList() for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(
depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (
i_layer < self.num_layers - 1) else None
)
self.layers.append(layer)
self.norm = norm_layer(self.num_features) if with_pool:
self.*gpool = nn.AdaptiveAvgPool1D(1)
if class_dim > 0:
self.head = nn.Linear(self.num_features, class_dim)
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_features(self, x):
x = self.patch_embed(x) if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x) for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
return x.transpose((0, 2, 1)) # B C 1
def forward(self, x):
x = self.forward_features(x) if self.with_pool:
x = self.*gpool(x)
if self.class_dim > 0:
x = paddle.flatten(x, 1)
x = self.head(x) return x
def get_transforms(resize, crop):
transforms = [T.Resize(resize, interpolation='bicubic')] if crop:
transforms.append(T.CenterCrop(crop))
transforms.append(T.ToTensor())
transforms.append(T.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
transforms = T.Compose(transforms) return transforms
transforms_224 = get_transforms(256, 224)
transforms_384 = get_transforms((384, 384), None)
def swin_ti(pretrained=False, **kwargs):
model = SwinTransformer(**kwargs) if pretrained:
model.set_dict(paddle.load('data/data80934/swin_tiny_patch4_window7_224.pdparams')) return model, transforms_224def swin_s(pretrained=False, **kwargs):
model = SwinTransformer(
depths=[2, 2, 18, 2],
num_heads=[3, 6, 12, 24]
** kwargs
) if pretrained:
model.set_dict(paddle.load('data/data80934/swin_small_patch4_window7_224.pdparams')) return model, transforms_224def swin_b(pretrained=False, **kwargs):
model = SwinTransformer(
embed_dim=128,
depths=[2, 2, 18, 2],
num_heads=[4, 8, 16, 32]
** kwargs
) if pretrained:
model.set_dict(paddle.load('data/data80934/swin_base_patch4_window7_224.pdparams')) return model, transforms_224def swin_b_384(pretrained=False, **kwargs):
model = SwinTransformer(
img_size=384,
embed_dim=128,
depths=[2, 2, 18, 2],
num_heads=[4, 8, 16, 32],
window_size=12,
**kwargs
) if pretrained:
model.set_dict(paddle.load('data/data80934/swin_base_patch4_window12_384.pdparams')) return model, transforms_384
# 解压数据集!mkdir ~/data/ILSVRC2012 !tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012
import osimport cv2import numpy as npimport paddle# from ppim import pit_b_distilledfrom PIL import Image# 构建数据集class ILSVRC2012(paddle.io.Dataset):
def __init__(self, root, label_list, transform, backend='pil'):
self.transform = transform
self.root = root
self.label_list = label_list
self.backend = backend
self.load_datas() def load_datas(self):
self.imgs = []
self.labels = [] with open(self.label_list, 'r') as f: for line in f:
img, label = line[:-1].split(' ')
self.imgs.append(os.path.join(self.root, img))
self.labels.append(int(label)) def __getitem__(self, idx):
label = self.labels[idx]
image = self.imgs[idx] if self.backend=='cv2':
image = cv2.imread(image) else:
image = Image.open(image).convert('RGB')
image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self):
return len(self.imgs)# 配置模型model, val_transforms = swin_ti(pretrained=True)
model = paddle.Model(model)
model.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 配置数据集val_dataset = ILSVRC2012('data/ILSVRC2012', transform=val_transforms, label_list='data/data68594/val_list.txt')# 模型验证model.evaluate(val_dataset, batch_size=512)
Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and
step 10/98 - acc_top1: 0.8164 - acc_top5: 0.9547 - 7s/step step 20/98 - acc_top1: 0.8155 - acc_top5: 0.9549 - 7s/step step 30/98 - acc_top1: 0.8113 - acc_top5: 0.9542 - 7s/step step 40/98 - acc_top1: 0.8113 - acc_top5: 0.9543 - 7s/step step 50/98 - acc_top1: 0.8115 - acc_top5: 0.9547 - 7s/step step 60/98 - acc_top1: 0.8115 - acc_top5: 0.9547 - 7s/step step 70/98 - acc_top1: 0.8107 - acc_top5: 0.9550 - 7s/step step 80/98 - acc_top1: 0.8116 - acc_top5: 0.9549 - 7s/step step 90/98 - acc_top1: 0.8113 - acc_top5: 0.9549 - 6s/step step 98/98 - acc_top1: 0.8119 - acc_top5: 0.9551 - 6s/step Eval samples: 50000
{'acc_top1': 0.81186, 'acc_top5': 0.9551}
以上就是Swin Transformer:层次化视觉 Transformer的详细内容,更多请关注其它相关文章!
# 才疏学浅
# 抖音做网站推广赚钱吗知乎
# 天猫女王节营销推广
# 江门社交媒体营销推广专业公司
# 一个人怎么推广网站卖货
# 帝国seo专用发布器
# 云购网站建设
# 花溪区seo排名
# 沈阳社区营销推广
# 通州房地产网站建设
# 贵州seo优化加盟
# 相关文章
# 就不
# 班门弄斧
# python
# 长风破浪
# 新到
# 官网
# 大佬
# 中文网
# 一言
# type
# latte
# asic
# red
# ai
# windows
相关栏目:
【
Google疑问12 】
【
Facebook疑问10 】
【
优化推广96088 】
【
技术知识133117 】
【
IDC资讯59369 】
【
网络运营7196 】
【
IT资讯61894 】
相关推荐:
V社回应拒绝上架含 AI 生成内容的游戏:审核政策正在调整中
字节、网易相继入局,AI之后大厂又找到下一个风口?
马斯克称未来机器人数量将多于人类,特斯拉愿共享自动驾驶技术
令人震惊的特斯拉机器人
生活垃圾智能分类机器人社区展“才能”,征求居民意见
人工智能在项目管理中的作用
微软Bing聊天机器人电脑端即将支持语音提问
随时随地,追踪每个像素,连遮挡都不怕的「追踪一切」视频算法来了
智能机器人与话剧的完美结合:宇树四足机器人B1助力《骆驼祥子》重现经典
类GPT模型训练提速26.5%,清华朱军等人用INT4算法加速神经网络训练
如何用AI开创智慧能源新时代?固德威正让能源“通人性”!
花16000元买四款扫拖机器人!科沃斯追觅石头小米谁能笑到最后?
AI在教育中的角色:AI如何改变我们的学习方式
Stability AI 推出文生图模型 SDXL0.9,GPU要求下探至消费级水平
一次购买全年省心,入手科沃斯这几台机器人,省下时间就是金钱
刊·见 | 捕捉人工智能领域最新动态?收藏Applied Artificial Intelligence
Snap宣布研发出新技术 可大幅提升AI生成图像速度
北京市元宇宙产业创新中心筹建工作正式启动
13 个提高生产力的 AI 工具
Moka AI产品后观察:HR SaaS迈进AGI时代
人脸识别+全景双摄+AI算法 萤石推动智能锁行业革新
网易加速行业AI大模型应用,将覆盖100多个应用场景
梦想实现!硬核科幻大片VR智能头盔即将问世
AI和ML推动联网设备的增长
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
苹果2万5的AR遭遇砍单95%:不及预期
优傲机器人的人机协作技术 助力中小企发展
塑造全能智能管家:华为小艺AI加成应对大模型挑战
应用生成式人工智能技术改善农业产业
NVIDIA垄断AI市场90%份额:AMD性能追上80% 软件太不能打
微软bing聊天推出AI购物工具 可进行比价并查看历史最低价
甲骨文与Cohere合作为企业提供生成式人工智能服务
日媒:AI高效解析纳斯卡地画
南京制造的国产工业机器人:在外资品牌竞争中突围,年销售1.8万台
日入400万,第一批AI骗子已上岗
猿力科技入选北京市通用人工智能产业创新伙伴计划
周星驰支持的人工智能与 Web3 初创公司 Moonbox 完成 100 万美元融资
华为推出两款商用 AI 大模型存储新品,支持 1200 万 IOPS 性能
人工智能正在弥合认知和表达之间的鸿沟
AYANEO AIR 1S 掌机发布:R7 7840U,预订价 4699 元起
WPS AI 官网上线:可申请体验官资格,支持 Windows、安卓端下载
清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳
华为云盘古大模型3.0发布 AI云服务同时上线:200亿亿次性能
云深处与昇腾CANN携手合作:开设ROS四足机器狗开发训练营
第四范式「式说」大模型入选《2025年通用人工智能创新应用案例集》
“上海市民营企业人工智能赋能创新中心”揭牌成立
iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了
美版贴吧8000小组自爆停摆!拒绝数据被谷歌OpenAI白嫖,CEO被网友骂翻:背刺第三方应用
MetaGPT AI 模型开源:可模拟软件公司开发过程,生成高质量代码
阿里云推出通义万相AI绘画大模型
2025-07-22

运城市盐湖区信雨科技有限公司是一家深耕海外推广领域十年的专业服务商,作为谷歌推广与Facebook广告全球合作伙伴,聚焦外贸企业出海痛点,以数字化营销为核心,提供一站式海外营销解决方案。公司凭借十年行业沉淀与平台官方资源加持,打破传统外贸获客壁垒,助力企业高效开拓全球市场,成为中小企业出海的可靠合作伙伴。

 c shift
if self.shift_size > 0:
x = paddle.roll(shifted_x, shifts=(
self.shift_size, self.shift_size), axis=(1, 2)) else:
x = shifted_x
x = x.reshape((B, H * W, C)) # FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x))) return xclass PatchMerging(nn.Layer):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias_attr=False)
self.norm = norm_layer(4 * dim) def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.reshape((B, H, W, C))
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = paddle.concat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.reshape((B, -1, 4 * C)) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x) return xclass BasicLayer(nn.Layer):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Layer | None, optional): Downsample layer at the end of the layer. Default: None
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth # build blocks
self.blocks = nn.LayerList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (
i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(
drop_path, np.ndarray) else drop_path,
norm_layer=norm_layer) for i in range(depth)]) # patch merging layer
if downsample is not None:
self.downsample = downsample(
input_resolution, dim=dim, norm_layer=norm_layer) else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
x = blk(x) if self.downsample is not None:
x = self.downsample(x) return xclass PatchEmbed(nn.Layer):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Layer, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] //
patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2D(in_chans, embed_dim,
kernel_size=patch_size, stride=patch_size) if norm_layer is not None:
self.norm = norm_layer(embed_dim) else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape # FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose((0, 2, 1)) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x) return xclass SwinTransformer(nn.Layer):
r""" Swin Transformer
A Paddle impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
class_dim (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Layer): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
class_dim=1000, with_pool=True, **kwargs):
super().__init__()
self.class_dim = class_dim
self.with_pool = with_pool
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio # split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution # absolute position embedding
if self.ape:
self.absolute_pos_embed = self.create_parameter(
shape=(1, num_patches, embed_dim),
default_initializer=zeros_
)
self.add_parameter("absolute_pos_embed", self.absolute_pos_embed)
trunc_normal_(self.absolute_pos_embed)
self.pos_drop = nn.Dropout(p=drop_rate) # stochastic depth
dpr = np.linspace(0, drop_path_rate, sum(depths)) # build layers
self.layers = nn.LayerList() for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(
depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (
i_layer < self.num_layers - 1) else None
)
self.layers.append(layer)
self.norm = norm_layer(self.num_features) if with_pool:
self.*gpool = nn.AdaptiveAvgPool1D(1)
if class_dim > 0:
self.head = nn.Linear(self.num_features, class_dim)
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_features(self, x):
x = self.patch_embed(x) if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x) for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
return x.transpose((0, 2, 1)) # B C 1
def forward(self, x):
x = self.forward_features(x) if self.with_pool:
x = self.*gpool(x)
if self.class_dim > 0:
x = paddle.flatten(x, 1)
x = self.head(x) return x
c shift
if self.shift_size > 0:
x = paddle.roll(shifted_x, shifts=(
self.shift_size, self.shift_size), axis=(1, 2)) else:
x = shifted_x
x = x.reshape((B, H * W, C)) # FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x))) return xclass PatchMerging(nn.Layer):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias_attr=False)
self.norm = norm_layer(4 * dim) def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.reshape((B, H, W, C))
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = paddle.concat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.reshape((B, -1, 4 * C)) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x) return xclass BasicLayer(nn.Layer):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Layer | None, optional): Downsample layer at the end of the layer. Default: None
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth # build blocks
self.blocks = nn.LayerList([
SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (
i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(
drop_path, np.ndarray) else drop_path,
norm_layer=norm_layer) for i in range(depth)]) # patch merging layer
if downsample is not None:
self.downsample = downsample(
input_resolution, dim=dim, norm_layer=norm_layer) else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
x = blk(x) if self.downsample is not None:
x = self.downsample(x) return xclass PatchEmbed(nn.Layer):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Layer, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] //
patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2D(in_chans, embed_dim,
kernel_size=patch_size, stride=patch_size) if norm_layer is not None:
self.norm = norm_layer(embed_dim) else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape # FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose((0, 2, 1)) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x) return xclass SwinTransformer(nn.Layer):
r""" Swin Transformer
A Paddle impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
class_dim (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Layer): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
class_dim=1000, with_pool=True, **kwargs):
super().__init__()
self.class_dim = class_dim
self.with_pool = with_pool
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio # split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution # absolute position embedding
if self.ape:
self.absolute_pos_embed = self.create_parameter(
shape=(1, num_patches, embed_dim),
default_initializer=zeros_
)
self.add_parameter("absolute_pos_embed", self.absolute_pos_embed)
trunc_normal_(self.absolute_pos_embed)
self.pos_drop = nn.Dropout(p=drop_rate) # stochastic depth
dpr = np.linspace(0, drop_path_rate, sum(depths)) # build layers
self.layers = nn.LayerList() for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(
depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (
i_layer < self.num_layers - 1) else None
)
self.layers.append(layer)
self.norm = norm_layer(self.num_features) if with_pool:
self.*gpool = nn.AdaptiveAvgPool1D(1)
if class_dim > 0:
self.head = nn.Linear(self.num_features, class_dim)
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_features(self, x):
x = self.patch_embed(x) if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x) for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
return x.transpose((0, 2, 1)) # B C 1
def forward(self, x):
x = self.forward_features(x) if self.with_pool:
x = self.*gpool(x)
if self.class_dim > 0:
x = paddle.flatten(x, 1)
x = self.head(x) return x